The "HiFi" Benchmark for Reliable AI Automation
The "HiFi" Benchmark for Reliable AI Automation
AI Reliability for IT Service Management
AI Reliability for IT Service Management
Highlights
We've published our February 2026 benchmark implementation results, achieving an industry-leading 99% AI Reliability score.
Resources:
Benchmark definition site
Benchmark results on Thunk.AI
Thunk.AI Website
Highlights
We've published our February 2026 benchmark implementation results, achieving an industry-leading 99% AI Reliability score.
Resources:
Benchmark definition site
Benchmark results on Thunk.AI
Thunk.AI Website
This article describes a new benchmark designed to measure the reliability of AI agentic automation as applied to IT Service Management scenarios.
The benchmark provides a detailed description of various scenario “arenas” used to represent realistic IT service management states in the real world, along with associated service tickets and their expected resolutions.
Thunk.AI has created an execution and evaluation harness so that any agentic implementation of the benchmark can be evaluated for AI Reliability. A generalized version of this harness is also available as a product offering for benchmarking and measurement of other scenarios.
Thunk.AI has demonstrated an implementation of the benchmark on the Thunk.AI enterprise automation platform. The results show that by utilizing the capabilities of the platform, 99% AI Reliability can be achieved using common LLMs like GPT-4.1, with only a 6% rate of escalation of edge cases to humans for resolution.
These results are particularly compelling when compared to a baseline naive agentic implementation that does not utilize any of the capabilities of the Thunk.AI platform. Those baseline results are significantly worse (86% AI Reliability with a 1% rate of escalation), and help explain why naive agentic solutions have failed to achieve enterprise traction.
The results demonstrate that with the right best-of-breed agentic platform, enterprise IT Service Management is primed for a large-scale shift to agentic automation.
1: The goals of the benchmark
AI agents can enable major productivity gains via the automation of human-intensive business processes. However, incorrect decisions and actions have significant negative consequences in enterprise environments. Customer adoption of AI automation has so far been hampered by a lack of confidence that AI agents/automation systems will indeed deliver results that have accuracy, consistency, and fidelity to the desired business process. Enterprise customers express these concerns as a lack of "AI Reliability".
There are many benchmarks that measure the accuracy of LLM models on specific agentic tasks. They focus on the LLM model rather than the agentic platform that harnesses the LLM model. None of them focus on repeatable business processes in an enterprise context.
The "HiFi" series of benchmarks created by Thunk.AI focuses instead on enterprise scenarios where AI agents are expected to automate business processes. These benchmarks provide a clear and measurable way for enterprise customers to evaluate agentic platforms, compare them, and decide whether to and how to automate business processes with AI agents.
This specific ITSM benchmark has four goals:
Provide a representative example of the broad class of IT Service Management (ITSM) processes.
Provide transparent data, instruction, and evaluation instructions, so that any agentic platform vendor or customer can evaluate the benchmark with different implementations. This benchmark is accompanied by a thorough and rich scenario simulator exposing data via MCP, along with a full evaluation harness for live evaluation of agentic implementations of the benchmark.
Provide meaningful metrics to measure AI reliability, compare and judge alternatives, and make platform decisions for ITSM agentic solutions.
Implement, measure, and demonstrate these metrics on implementations of the benchmark. We begin with an implementation on the Thunk.AI platform. The results (6% human escalation rate, with 99+% reliability for the fully automated cases) using the GPT-4.1 LLM show that with the right platform, enterprise-grade AI reliability can be achieved using commonly available and affordable AI models.
The value is not limited to just this one benchmark scenario. A version of the tool used for benchmark scenario construction, simulation, and evaluation framework is also available as a product offering for enterprise customers.
2: The IT Service Management domain
IT Service Management (ITSM) is a critical business function in every enterprise. Organizations invest significant resources in monitoring, troubleshooting, and resolving IT infrastructure issues to maintain business continuity. The general pattern of an IT service management process involves (a) receiving incident reports from users, (b) diagnosing the underlying technical problems, and (c) taking appropriate corrective actions or escalating to human specialists when necessary.
This benchmark implements a realistic ITSM workflow that handles diverse IT incident tickets across multiple infrastructure categories including web applications, databases, network services, cloud resources, and authentication systems. The workflow reflects scenarios that every enterprise IT team encounters regularly, making it broadly applicable and highly relevant for evaluating AI automation capabilities.
The complexity and importance of ITSM make it an ideal domain for evaluating AI reliability. Incorrect diagnoses or actions can lead to service outages, data loss, or security vulnerabilities. At the same time, the potential for automation is enormous—enterprises handle hundreds or thousands of routine IT incidents that follow predictable patterns and could be resolved automatically if AI systems were sufficiently reliable.
There are three logical stages in an ITSM incident resolution workflow:
Validate ticket and gather information
Incident tickets arrive from end users who may describe problems in non-technical terms (e.g., "website is slow", "can't log in", "database error"). The system must validate that the ticket contains sufficient information and query the appropriate IT services and monitoring systems to validate the information provided in the ticket.Diagnose the problem (RCA)
Using both the user's report and technical data gathered from monitoring systems, for both the affected service and the recursive set of services it depends on, the AI agent must identify the root cause of the issue. This requires understanding relationships between services, interpreting error codes and log messages, analyzing performance metrics, and correlating symptoms with known failure patterns.Ignore/resolve, take action, or escalate
Based on the diagnosis, the system must determine if the issue can be safely resolved through automated corrective action (such as restarting a service, clearing a cache, updating a configuration, or scaling resources) or if it requires human intervention. This decision balances the confidence in the diagnosis, the risk of the proposed action, and the impact on business operations. When uncertain, the system must err on the side of escalation.
3: Benchmark methodology
The benchmark is described in detail in the appendix section. The concise summary is presented here.
3.1. Workflow design
The three-stage ITSM workflow described in Section 2 represents the desired high-level process structure. The expected actions at each stage vary significantly depending on the nature of the incident, the affected infrastructure components, and the diagnostic findings. The entire description of the workflow (all logic, all constraints, all intended actions, all domain knowledge) is provided in natural language (English) as is appropriate for agentic solutions.
The agentic automation is expected to operate on the benchmark by processing each incident ticket as an independent workflow instance, validating the ticket, making a diagnosis, and taking an appropriate action. When necessary, the agentic automation can escalate to a human for intervention (before diagnosis, after diagnosis, or with a suggestion of the action to take).
3.2. Metrics and metric evaluation
We define the two top-level metrics that are meaningful for ALL agentic workflows:
Escalation Rate (%): the fraction of workflow instances that are escalated by the AI agent to a human for intervention.
AI Reliability (%): the fraction of (non-escalated) workflow instances where the AI agent makes the right diagnosis as well as takes the right action.
The lower the escalation rate, the greater the human productivity gain from automating work with agentic AI. The lower the reliability however, the greater the potential for harm caused by agentic AI.
For the technical AI practitioner, the Escalation Rate is a measure of Recall, and the AI Reliability is a measure of Precision. For this specific ITSM workflow benchmark, there are also two sub-steps with similar metrics of interest:
Diagnosis (Escalation Rate and AI Reliability): What fraction of the workflow instances are flagged for human diagnosis, and of those diagnosed by AI, how often does it get it right?
Resolution (Escalation Rate and AI Reliability): What fraction of the workflow instances are flagged for human action, and of those resolved by AI, how often does it get it right?
Given the criticality of ITSM workflows, most enterprise customers would prefer to have agentic solutions that maximize AI Reliability, with as low an Escalation rate as possible.
3.3. Benchmark data set
The benchmark models 20 distinct IT infrastructure scenarios at an E-Commerce site, each representing a realistic technical environment state with (a) services and infrastructure components (web servers, databases, authentication systems, APIs, message queues, caching layers, CDN services, monitoring systems), (b) observable state (service status, performance metrics, error logs, configuration parameters, resource utilization, connection counts, response times, and health check results), and (c) available actions (service restarts, configuration updates, cache clearing, resource scaling, connection resets, log rotation, and other standard remediation operations). For each scenario, multiple incident tickets (approximately 5 per scenario, totaling 100 tickets) are created modeling how actual end users would report IT problems. The ground truth (the expected workflow behavior and results) for the benchmark data set was created through manual expert analysis.
3.4. Benchmark evaluation
Each of these scenarios is materialized into a measurement “Arena” – a set of MCP (Model Context Protocol) servers that provide programmatic access to the simulated IT infrastructure, allowing AI agents to query service status, retrieve metrics, read logs, and execute actions exactly as they would in a real enterprise environment. There is a Benchmark Evaluator that instantiates the measurement arena for each scenario, initiates the workflow against the agentic implementation, and captures the results. After all the workflows have completed, the Benchmark Evaluator compares the results against the ground truth, and constructs a detailed analysis report listing top-level metrics and a variety of deeper metrics.
4: Benchmark implementation results
This ITSM HiFi benchmark was implemented as described on the Thunk.AI platform utilizing its high-reliability features to optimize outcomes. The workflow definition strictly adhered to the representation provided in the benchmark definition. The Thunk.AI platform was configured to:
Represent the ITSM workflow as a “thunk” workflow with explicit steps for information gathering, diagnosis, and action execution
Utilize various unique elements of the Thunk.AI application model and runtime engine that are optimized for AI reliability
Utilize conservative escalation policies, preferring human intervention over potentially incorrect automated actions.
4.1. Results using the GPT-4.1 model
Escalation Rate 6% |
AI Reliability 99% |
These results demonstrate that Thunk.AI achieved reliable automation on the vast majority of IT incidents while appropriately escalating edge cases that required human judgment.
4.2. Detailed breakdown of results
The full results of the benchmark implementation on Thunk.AI show the details of how every ticket was processed, including analyses of incorrect escalations, incorrect diagnoses, and incorrect actions.
Diagnoses
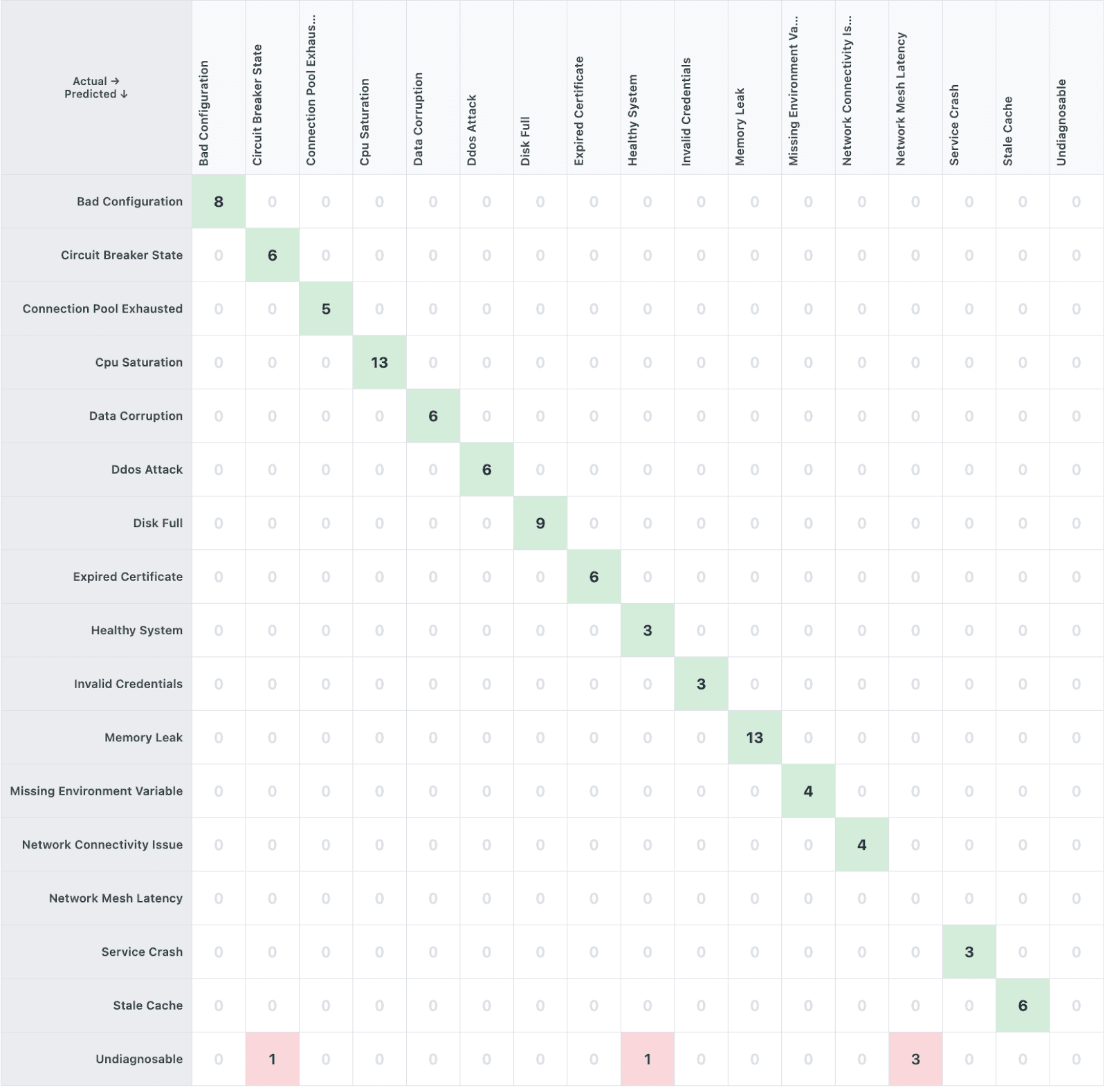
The chart shows that in 5 cases, the AI agent could not make a diagnosis. Three of these cases were all related to tickets in the same scenario. This is a particularly thorny scenario where the tickets indicated that the service was showing high latency. All the observability tools showed that (a) there was high latency, but (b) all the services were operating normally. The expected correct diagnosis is “network_mesh_latency”, by process of elimination and logical reasoning. However, the instructions provided no guidance for such a diagnosis. The agent would need to reach this conclusion from its world knowledge, but instead it decided to play it safe and return an "undiagnosable" decision. While we could have modified the benchmark to provide clarity for this scenario, we decided that this better reflects real-world situations. The instructions provided to an AI agent are always incomplete for some edge cases, and it is good to test that the agent decided to escalate rather than make the wrong decision.
Escalations
All but one of the escalations was because there was no confidence in the agent’s diagnosis of the issue. In the one other case, although it got the diagnosis correct, it decided to escalate because it wasn’t confident in which mitigation action to take.

Invalid Actions
The one invalid action was a case where the right action was to reset a circuit breaker, the agent correctly identified this, it also identified that it doesn’t have the permission to do this. Instead of escalating as per instructions, it chose to take the next best action which is to restart the service. This is an opportunity for improvement.
4.3. Comparison: Standard Baseline
To demonstrate the importance of platform architecture, we ran a baseline comparison using the very same GPT-4.1 model with minimal platform scaffolding. In this configuration, we simply provided the identical workflow description to the language model without structured workflow state, verification, constraint management, or specialized context handling. The same tools and content were provided. This standard baseline represents typical AI agentic automation platforms that are just wrapper loops over LLM APIs without any sophisticated context and reliability engineering.
Platform | Escalation Rate | AI Reliability |
Thunk.AI | 6% | 99+% |
Standard Baseline | 1% | 86% |
The baseline approach showed significantly worse AI reliability (only 86%). The lower rate of escalation (1%) is problematic because instead of escalating to a human “in the loop”, the agent overconfidently took incorrect actions that potentially led to the wrong outcomes. Overall, it took incorrect automated actions in 14% of tickets — actions that could cause service disruptions in a production environment.
This comparison underscores why a best-of-breed AI agentic platform like Thunk.AI is essential for enterprise AI reliability. The same language model produces different reliability outcomes depending on the platform architecture surrounding it. AI reliability in agentic workflows is largely determined by platform capabilities—how the platform represents workflows, scaffolds LLM reasoning, manages context and constraints, and implements verification mechanisms—rather than by the underlying LLM.
4.4. Summary of Key Findings
High reliability is achievable: With proper platform architecture, AI can reliably automate complex IT service management workflows.
The choice of optimal platform matter: The same benchmark shows very different results without the Thunk.AI platform optimizations that enhance AI Reliability.
Safety and autonomy can be effectively balanced: It is possible (and necessary) to achieve the right balance between safety (escalate when in doubt) and autonomy (correctly automate as much as possible).
Overall, Thunk.AI’s measured performance on this realistic but complex workload (99%+ AI reliability on 94% of cases) is a remarkably positive result. It signals that enterprise IT Service Management is ready for large-scale agentic automation.
5: Appendix: Benchmark details
The complete data set for this benchmark, including all IT scenarios, service definitions, incident tickets, MCP server interfaces, workflow descriptions, ground truth diagnoses and actions, and metric definitions are published for full transparency at the Benchmark Definition Site.
5.1. Workflow design
The ITSM workflow is described in natural language with the following high-level procedure:
Step 1 - Ticket Validation: Verify that the incident ticket contains sufficient information to proceed. If the ticket is unclear, ambiguous, or appears to be spam or a test, record that the ticket is not verifiable.
Step 2 - Diagnosis and Root Cause Analysis: Based on the ticket description, identify which IT services and infrastructure components are potentially affected. Gather sufficient technical data (status, metrics, logs, and configuration of relevant services) to enable accurate diagnosis. The diagnosis should explain both why the user is experiencing the reported problem and what underlying technical issue is causing it.
Step 3 - Action: Determine whether to escalate to a human or take automated corrective action. Escalate if:
The diagnosis is uncertain or multiple root causes are possible
The required action could have significant business impact (e.g., service restart during business hours)
The problem appears to be novel or outside normal operational patterns
No safe automated remediation is available
If proceeding with automated action, execute the specific corrective action that addresses the diagnosed root cause. Document the action taken and verify that it resolved the issue.
5.2. Benchmark “Arenas” – Modeling IT Environments
The benchmark includes 20 distinct realistic scenarios within the technical environment of an E-Commerce site. The environment includes:
Services and infrastructure components: Web servers, databases, authentication systems, APIs, message queues, caching layers, CDN services, monitoring systems, and more
Observable state: Service status, performance metrics, error logs, configuration parameters, resource utilization, connection counts, response times, and health check results
Available actions: Service restarts, configuration updates, cache clearing, resource scaling, connection resets, log rotation, and other standard remediation operations
The benchmark defines 20 common enterprise IT scenarios like:
Web application performance issues (slow page loads, high latency)
Database connectivity and performance problems
Authentication and authorization failures
API service errors and timeouts
Network connectivity issues
Cache invalidation and stale data problems
Cloud resource scaling issues
Message queue backlogs and processing delays
CDN and content delivery problems
Service configuration errors
Each such scenario is modeled as an “Arena” and hydrated into a set of MCP (Model Context Protocol) servers that provide programmatic access to the simulated IT infrastructure, allowing AI agents to query service status, retrieve metrics, read logs, and execute actions exactly as they would in a real enterprise environment. This approach ensures the benchmark tests realistic AI capabilities including tool use, multi-step reasoning, and decision-making under uncertainty.
As an example, here is one specific scenario description that is used to generate context data for a test arena.

5.3. Incident tickets
For each scenario, multiple incident tickets (approximately 5 per scenario, totaling 100 tickets) were created reflecting how actual end users would report IT problems. The tickets vary in:
Specificity: Some tickets are vague ("system is slow"), others more specific ("getting 504 errors on checkout page")
Technical detail: Some users include error messages or technical observations, others do not
Clarity: Some tickets clearly point to one component, others describe symptoms that could have multiple causes
This variation reflects real enterprise helpdesk experiences where user reports range from precise technical descriptions to general complaints about system behavior.
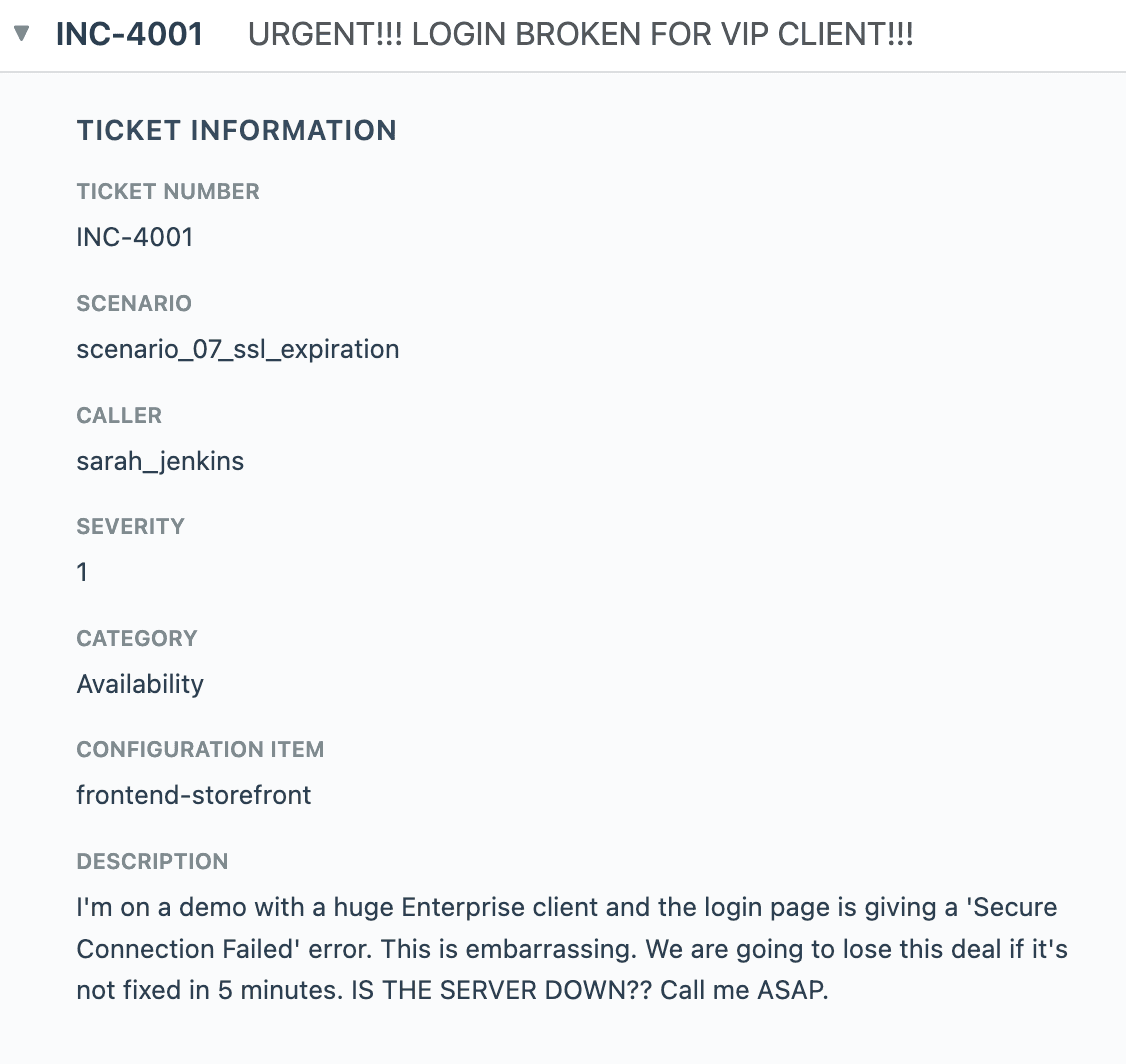
As an example, here is one ticket generated for one of the scenario arenas.
5.4. Ground truth and evaluation
The ground truth (what is "correct") for this benchmark is determined through manual expert analysis of each incident ticket. For each of the 100 tickets, IT professionals with domain expertise:
Identified the correct root cause diagnosis
Determined the appropriate corrective action
Specified whether the issue should be escalated or automated based on risk assessment
This ground truth represents what a well-trained IT operations professional would do when following the specified workflow procedures and exercising appropriate judgment. AI system outputs are compared against this ground truth using both exact matching (for structured outputs like action names) and semantic similarity (for diagnoses and explanations).
5.5. Benchmark variations
The benchmark can be run with different LLM models to evaluate the ability of the agentic platform to address the variability between LLM models. In practice, the latest frontier models may have higher quality, but they are also much more expensive and slow. Therefore, it is of interest to measure how much AI Reliability can be achieved with fast and inexpensive LLM models
The benchmark can also be generated with different variations to model specific enterprise scenarios:
Different infrastructure scenarios (cloud vs. on-premise, specific technology stacks)
Different service complexity levels (microservices vs. monolithic architectures)
Different ticket volumes and distributions
Different noise levels in monitoring data
Different escalation policies (conservative vs. aggressive automation)
Logically equivalent but alternative descriptions of the ITSM process and configuration.
5.6. Acceptable implementation guidelines
A valid implementation of this benchmark should follow these guidelines:
The workflow description, the IT scenarios, and the incident tickets should not be augmented with additional scenario-specific detail by a human implementer. However, they may be reformatted in ways appropriate to the specific platform implementation.
The workflow description can be augmented by AI agentic "reasoning" or "planning" logic automatically.
Neither the underlying AI models nor the instructions should include or be trained on any test data or labeled results from this benchmark.
The implementation may make commonly available AI tools accessible to agents, but should not create custom tools with specific domain knowledge of this benchmark.
The implementation can use any foundation AI models that are not fine-tuned to this data set.
5.7. Guidance on use
The methodology of this benchmark is broadly applicable beyond the specific IT scenarios chosen. The framework can be adapted to evaluate AI automation in other technical operations domains such as DevOps, security incident response, or infrastructure monitoring. This benchmark may be used:
As-is for evaluating ITSM automation capabilities across different agentic platform vendors or to evaluate the reliability of one solution with different LLM models
With variations (different scenarios, ticket volumes, escalation policies) to match specific enterprise environments
As a template for creating benchmarks in related operational domains
The same benchmark may be evaluated against various agentic platform implementations as long as they conform to the acceptable implementation guidelines. AI agentic platform vendors may describe and publicize their HiFi benchmark results as long as they appropriately attribute this document as the source of the benchmark. Any reporting of benchmark results should include the LLM model used, the agentic platform used, and a publicly available implementation. Enterprise customers may use this benchmark as a framework for evaluating internal and external implementations of AI automation for their IT operations.
Learn more
Benchmark definition site: https://github.com/ThunkAI/itsm-benchmark/
Benchmark results: https://docs.thunk.ai/benchmarks/itsm-benchmark-2026-02-20/gpt41.html
Thunk.AI Website: https://www.thunk.ai
This article describes a new benchmark designed to measure the reliability of AI agentic automation as applied to IT Service Management scenarios.
The benchmark provides a detailed description of various scenario “arenas” used to represent realistic IT service management states in the real world, along with associated service tickets and their expected resolutions.
Thunk.AI has created an execution and evaluation harness so that any agentic implementation of the benchmark can be evaluated for AI Reliability. A generalized version of this harness is also available as a product offering for benchmarking and measurement of other scenarios.
Thunk.AI has demonstrated an implementation of the benchmark on the Thunk.AI enterprise automation platform. The results show that by utilizing the capabilities of the platform, 99% AI Reliability can be achieved using common LLMs like GPT-4.1, with only a 6% rate of escalation of edge cases to humans for resolution.
These results are particularly compelling when compared to a baseline naive agentic implementation that does not utilize any of the capabilities of the Thunk.AI platform. Those baseline results are significantly worse (86% AI Reliability with a 1% rate of escalation), and help explain why naive agentic solutions have failed to achieve enterprise traction.
The results demonstrate that with the right best-of-breed agentic platform, enterprise IT Service Management is primed for a large-scale shift to agentic automation.
1: The goals of the benchmark
AI agents can enable major productivity gains via the automation of human-intensive business processes. However, incorrect decisions and actions have significant negative consequences in enterprise environments. Customer adoption of AI automation has so far been hampered by a lack of confidence that AI agents/automation systems will indeed deliver results that have accuracy, consistency, and fidelity to the desired business process. Enterprise customers express these concerns as a lack of "AI Reliability".
There are many benchmarks that measure the accuracy of LLM models on specific agentic tasks. They focus on the LLM model rather than the agentic platform that harnesses the LLM model. None of them focus on repeatable business processes in an enterprise context.
The "HiFi" series of benchmarks created by Thunk.AI focuses instead on enterprise scenarios where AI agents are expected to automate business processes. These benchmarks provide a clear and measurable way for enterprise customers to evaluate agentic platforms, compare them, and decide whether to and how to automate business processes with AI agents.
This specific ITSM benchmark has four goals:
Provide a representative example of the broad class of IT Service Management (ITSM) processes.
Provide transparent data, instruction, and evaluation instructions, so that any agentic platform vendor or customer can evaluate the benchmark with different implementations. This benchmark is accompanied by a thorough and rich scenario simulator exposing data via MCP, along with a full evaluation harness for live evaluation of agentic implementations of the benchmark.
Provide meaningful metrics to measure AI reliability, compare and judge alternatives, and make platform decisions for ITSM agentic solutions.
Implement, measure, and demonstrate these metrics on implementations of the benchmark. We begin with an implementation on the Thunk.AI platform. The results (6% human escalation rate, with 99+% reliability for the fully automated cases) using the GPT-4.1 LLM show that with the right platform, enterprise-grade AI reliability can be achieved using commonly available and affordable AI models.
The value is not limited to just this one benchmark scenario. A version of the tool used for benchmark scenario construction, simulation, and evaluation framework is also available as a product offering for enterprise customers.
2: The IT Service Management domain
IT Service Management (ITSM) is a critical business function in every enterprise. Organizations invest significant resources in monitoring, troubleshooting, and resolving IT infrastructure issues to maintain business continuity. The general pattern of an IT service management process involves (a) receiving incident reports from users, (b) diagnosing the underlying technical problems, and (c) taking appropriate corrective actions or escalating to human specialists when necessary.
This benchmark implements a realistic ITSM workflow that handles diverse IT incident tickets across multiple infrastructure categories including web applications, databases, network services, cloud resources, and authentication systems. The workflow reflects scenarios that every enterprise IT team encounters regularly, making it broadly applicable and highly relevant for evaluating AI automation capabilities.
The complexity and importance of ITSM make it an ideal domain for evaluating AI reliability. Incorrect diagnoses or actions can lead to service outages, data loss, or security vulnerabilities. At the same time, the potential for automation is enormous—enterprises handle hundreds or thousands of routine IT incidents that follow predictable patterns and could be resolved automatically if AI systems were sufficiently reliable.
There are three logical stages in an ITSM incident resolution workflow:
Validate ticket and gather information
Incident tickets arrive from end users who may describe problems in non-technical terms (e.g., "website is slow", "can't log in", "database error"). The system must validate that the ticket contains sufficient information and query the appropriate IT services and monitoring systems to validate the information provided in the ticket.Diagnose the problem (RCA)
Using both the user's report and technical data gathered from monitoring systems, for both the affected service and the recursive set of services it depends on, the AI agent must identify the root cause of the issue. This requires understanding relationships between services, interpreting error codes and log messages, analyzing performance metrics, and correlating symptoms with known failure patterns.Ignore/resolve, take action, or escalate
Based on the diagnosis, the system must determine if the issue can be safely resolved through automated corrective action (such as restarting a service, clearing a cache, updating a configuration, or scaling resources) or if it requires human intervention. This decision balances the confidence in the diagnosis, the risk of the proposed action, and the impact on business operations. When uncertain, the system must err on the side of escalation.
3: Benchmark methodology
The benchmark is described in detail in the appendix section. The concise summary is presented here.
3.1. Workflow design
The three-stage ITSM workflow described in Section 2 represents the desired high-level process structure. The expected actions at each stage vary significantly depending on the nature of the incident, the affected infrastructure components, and the diagnostic findings. The entire description of the workflow (all logic, all constraints, all intended actions, all domain knowledge) is provided in natural language (English) as is appropriate for agentic solutions.
The agentic automation is expected to operate on the benchmark by processing each incident ticket as an independent workflow instance, validating the ticket, making a diagnosis, and taking an appropriate action. When necessary, the agentic automation can escalate to a human for intervention (before diagnosis, after diagnosis, or with a suggestion of the action to take).
3.2. Metrics and metric evaluation
We define the two top-level metrics that are meaningful for ALL agentic workflows:
Escalation Rate (%): the fraction of workflow instances that are escalated by the AI agent to a human for intervention.
AI Reliability (%): the fraction of (non-escalated) workflow instances where the AI agent makes the right diagnosis as well as takes the right action.
The lower the escalation rate, the greater the human productivity gain from automating work with agentic AI. The lower the reliability however, the greater the potential for harm caused by agentic AI.
For the technical AI practitioner, the Escalation Rate is a measure of Recall, and the AI Reliability is a measure of Precision. For this specific ITSM workflow benchmark, there are also two sub-steps with similar metrics of interest:
Diagnosis (Escalation Rate and AI Reliability): What fraction of the workflow instances are flagged for human diagnosis, and of those diagnosed by AI, how often does it get it right?
Resolution (Escalation Rate and AI Reliability): What fraction of the workflow instances are flagged for human action, and of those resolved by AI, how often does it get it right?
Given the criticality of ITSM workflows, most enterprise customers would prefer to have agentic solutions that maximize AI Reliability, with as low an Escalation rate as possible.
3.3. Benchmark data set
The benchmark models 20 distinct IT infrastructure scenarios at an E-Commerce site, each representing a realistic technical environment state with (a) services and infrastructure components (web servers, databases, authentication systems, APIs, message queues, caching layers, CDN services, monitoring systems), (b) observable state (service status, performance metrics, error logs, configuration parameters, resource utilization, connection counts, response times, and health check results), and (c) available actions (service restarts, configuration updates, cache clearing, resource scaling, connection resets, log rotation, and other standard remediation operations). For each scenario, multiple incident tickets (approximately 5 per scenario, totaling 100 tickets) are created modeling how actual end users would report IT problems. The ground truth (the expected workflow behavior and results) for the benchmark data set was created through manual expert analysis.
3.4. Benchmark evaluation
Each of these scenarios is materialized into a measurement “Arena” – a set of MCP (Model Context Protocol) servers that provide programmatic access to the simulated IT infrastructure, allowing AI agents to query service status, retrieve metrics, read logs, and execute actions exactly as they would in a real enterprise environment. There is a Benchmark Evaluator that instantiates the measurement arena for each scenario, initiates the workflow against the agentic implementation, and captures the results. After all the workflows have completed, the Benchmark Evaluator compares the results against the ground truth, and constructs a detailed analysis report listing top-level metrics and a variety of deeper metrics.
4: Benchmark implementation results
This ITSM HiFi benchmark was implemented as described on the Thunk.AI platform utilizing its high-reliability features to optimize outcomes. The workflow definition strictly adhered to the representation provided in the benchmark definition. The Thunk.AI platform was configured to:
Represent the ITSM workflow as a “thunk” workflow with explicit steps for information gathering, diagnosis, and action execution
Utilize various unique elements of the Thunk.AI application model and runtime engine that are optimized for AI reliability
Utilize conservative escalation policies, preferring human intervention over potentially incorrect automated actions.
4.1. Results using the GPT-4.1 model
Escalation Rate 6% |
AI Reliability 99% |
These results demonstrate that Thunk.AI achieved reliable automation on the vast majority of IT incidents while appropriately escalating edge cases that required human judgment.
4.2. Detailed breakdown of results
The full results of the benchmark implementation on Thunk.AI show the details of how every ticket was processed, including analyses of incorrect escalations, incorrect diagnoses, and incorrect actions.
Diagnoses
The chart shows that in 5 cases, the AI agent could not make a diagnosis. Three of these cases were all related to tickets in the same scenario. This is a particularly thorny scenario where the tickets indicated that the service was showing high latency. All the observability tools showed that (a) there was high latency, but (b) all the services were operating normally. The expected correct diagnosis is “network_mesh_latency”, by process of elimination and logical reasoning. However, the instructions provided no guidance for such a diagnosis. The agent would need to reach this conclusion from its world knowledge, but instead it decided to play it safe and return an "undiagnosable" decision. While we could have modified the benchmark to provide clarity for this scenario, we decided that this better reflects real-world situations. The instructions provided to an AI agent are always incomplete for some edge cases, and it is good to test that the agent decided to escalate rather than make the wrong decision.
Escalations
All but one of the escalations was because there was no confidence in the agent’s diagnosis of the issue. In the one other case, although it got the diagnosis correct, it decided to escalate because it wasn’t confident in which mitigation action to take.
Invalid Actions
The one invalid action was a case where the right action was to reset a circuit breaker, the agent correctly identified this, it also identified that it doesn’t have the permission to do this. Instead of escalating as per instructions, it chose to take the next best action which is to restart the service. This is an opportunity for improvement.
4.3. Comparison: Standard Baseline
To demonstrate the importance of platform architecture, we ran a baseline comparison using the very same GPT-4.1 model with minimal platform scaffolding. In this configuration, we simply provided the identical workflow description to the language model without structured workflow state, verification, constraint management, or specialized context handling. The same tools and content were provided. This standard baseline represents typical AI agentic automation platforms that are just wrapper loops over LLM APIs without any sophisticated context and reliability engineering.
Platform | Escalation Rate | AI Reliability |
Thunk.AI | 6% | 99+% |
Standard Baseline | 1% | 86% |
The baseline approach showed significantly worse AI reliability (only 86%). The lower rate of escalation (1%) is problematic because instead of escalating to a human “in the loop”, the agent overconfidently took incorrect actions that potentially led to the wrong outcomes. Overall, it took incorrect automated actions in 14% of tickets — actions that could cause service disruptions in a production environment.
This comparison underscores why a best-of-breed AI agentic platform like Thunk.AI is essential for enterprise AI reliability. The same language model produces different reliability outcomes depending on the platform architecture surrounding it. AI reliability in agentic workflows is largely determined by platform capabilities—how the platform represents workflows, scaffolds LLM reasoning, manages context and constraints, and implements verification mechanisms—rather than by the underlying LLM.
4.4. Summary of Key Findings
High reliability is achievable: With proper platform architecture, AI can reliably automate complex IT service management workflows.
The choice of optimal platform matter: The same benchmark shows very different results without the Thunk.AI platform optimizations that enhance AI Reliability.
Safety and autonomy can be effectively balanced: It is possible (and necessary) to achieve the right balance between safety (escalate when in doubt) and autonomy (correctly automate as much as possible).
Overall, Thunk.AI’s measured performance on this realistic but complex workload (99%+ AI reliability on 94% of cases) is a remarkably positive result. It signals that enterprise IT Service Management is ready for large-scale agentic automation.
5: Appendix: Benchmark details
The complete data set for this benchmark, including all IT scenarios, service definitions, incident tickets, MCP server interfaces, workflow descriptions, ground truth diagnoses and actions, and metric definitions are published for full transparency at the Benchmark Definition Site.
5.1. Workflow design
The ITSM workflow is described in natural language with the following high-level procedure:
Step 1 - Ticket Validation: Verify that the incident ticket contains sufficient information to proceed. If the ticket is unclear, ambiguous, or appears to be spam or a test, record that the ticket is not verifiable.
Step 2 - Diagnosis and Root Cause Analysis: Based on the ticket description, identify which IT services and infrastructure components are potentially affected. Gather sufficient technical data (status, metrics, logs, and configuration of relevant services) to enable accurate diagnosis. The diagnosis should explain both why the user is experiencing the reported problem and what underlying technical issue is causing it.
Step 3 - Action: Determine whether to escalate to a human or take automated corrective action. Escalate if:
The diagnosis is uncertain or multiple root causes are possible
The required action could have significant business impact (e.g., service restart during business hours)
The problem appears to be novel or outside normal operational patterns
No safe automated remediation is available
If proceeding with automated action, execute the specific corrective action that addresses the diagnosed root cause. Document the action taken and verify that it resolved the issue.
5.2. Benchmark “Arenas” – Modeling IT Environments
The benchmark includes 20 distinct realistic scenarios within the technical environment of an E-Commerce site. The environment includes:
Services and infrastructure components: Web servers, databases, authentication systems, APIs, message queues, caching layers, CDN services, monitoring systems, and more
Observable state: Service status, performance metrics, error logs, configuration parameters, resource utilization, connection counts, response times, and health check results
Available actions: Service restarts, configuration updates, cache clearing, resource scaling, connection resets, log rotation, and other standard remediation operations
The benchmark defines 20 common enterprise IT scenarios like:
Web application performance issues (slow page loads, high latency)
Database connectivity and performance problems
Authentication and authorization failures
API service errors and timeouts
Network connectivity issues
Cache invalidation and stale data problems
Cloud resource scaling issues
Message queue backlogs and processing delays
CDN and content delivery problems
Service configuration errors
Each such scenario is modeled as an “Arena” and hydrated into a set of MCP (Model Context Protocol) servers that provide programmatic access to the simulated IT infrastructure, allowing AI agents to query service status, retrieve metrics, read logs, and execute actions exactly as they would in a real enterprise environment. This approach ensures the benchmark tests realistic AI capabilities including tool use, multi-step reasoning, and decision-making under uncertainty.
As an example, here is one specific scenario description that is used to generate context data for a test arena.
5.3. Incident tickets
For each scenario, multiple incident tickets (approximately 5 per scenario, totaling 100 tickets) were created reflecting how actual end users would report IT problems. The tickets vary in:
Specificity: Some tickets are vague ("system is slow"), others more specific ("getting 504 errors on checkout page")
Technical detail: Some users include error messages or technical observations, others do not
Clarity: Some tickets clearly point to one component, others describe symptoms that could have multiple causes
This variation reflects real enterprise helpdesk experiences where user reports range from precise technical descriptions to general complaints about system behavior.
As an example, here is one ticket generated for one of the scenario arenas.
5.4. Ground truth and evaluation
The ground truth (what is "correct") for this benchmark is determined through manual expert analysis of each incident ticket. For each of the 100 tickets, IT professionals with domain expertise:
Identified the correct root cause diagnosis
Determined the appropriate corrective action
Specified whether the issue should be escalated or automated based on risk assessment
This ground truth represents what a well-trained IT operations professional would do when following the specified workflow procedures and exercising appropriate judgment. AI system outputs are compared against this ground truth using both exact matching (for structured outputs like action names) and semantic similarity (for diagnoses and explanations).
5.5. Benchmark variations
The benchmark can be run with different LLM models to evaluate the ability of the agentic platform to address the variability between LLM models. In practice, the latest frontier models may have higher quality, but they are also much more expensive and slow. Therefore, it is of interest to measure how much AI Reliability can be achieved with fast and inexpensive LLM models
The benchmark can also be generated with different variations to model specific enterprise scenarios:
Different infrastructure scenarios (cloud vs. on-premise, specific technology stacks)
Different service complexity levels (microservices vs. monolithic architectures)
Different ticket volumes and distributions
Different noise levels in monitoring data
Different escalation policies (conservative vs. aggressive automation)
Logically equivalent but alternative descriptions of the ITSM process and configuration.
5.6. Acceptable implementation guidelines
A valid implementation of this benchmark should follow these guidelines:
The workflow description, the IT scenarios, and the incident tickets should not be augmented with additional scenario-specific detail by a human implementer. However, they may be reformatted in ways appropriate to the specific platform implementation.
The workflow description can be augmented by AI agentic "reasoning" or "planning" logic automatically.
Neither the underlying AI models nor the instructions should include or be trained on any test data or labeled results from this benchmark.
The implementation may make commonly available AI tools accessible to agents, but should not create custom tools with specific domain knowledge of this benchmark.
The implementation can use any foundation AI models that are not fine-tuned to this data set.
5.7. Guidance on use
The methodology of this benchmark is broadly applicable beyond the specific IT scenarios chosen. The framework can be adapted to evaluate AI automation in other technical operations domains such as DevOps, security incident response, or infrastructure monitoring. This benchmark may be used:
As-is for evaluating ITSM automation capabilities across different agentic platform vendors or to evaluate the reliability of one solution with different LLM models
With variations (different scenarios, ticket volumes, escalation policies) to match specific enterprise environments
As a template for creating benchmarks in related operational domains
The same benchmark may be evaluated against various agentic platform implementations as long as they conform to the acceptable implementation guidelines. AI agentic platform vendors may describe and publicize their HiFi benchmark results as long as they appropriately attribute this document as the source of the benchmark. Any reporting of benchmark results should include the LLM model used, the agentic platform used, and a publicly available implementation. Enterprise customers may use this benchmark as a framework for evaluating internal and external implementations of AI automation for their IT operations.
Learn more
Benchmark definition site: https://github.com/ThunkAI/itsm-benchmark/
Benchmark results: https://docs.thunk.ai/benchmarks/itsm-benchmark-2026-02-20/gpt41.html
Thunk.AI Website: https://www.thunk.ai